自来水厂到你家的水管网是一个复杂的有向图,每一节水管都有一个最大承载流量。
有一个汇点(你家),一个源点(自来水厂),和若干的边(管道),水一定是从源点流向汇点。
本文中,我们用 f ( u , v ) f(u, v) f ( u , v ) ( u , v ) (u, v) ( u , v ) c ( u , v ) c(u, v) c ( u , v ) ( u , v ) (u, v) ( u , v ) c f ( u , v ) = c ( u , v ) − f ( u , v ) c_f(u, v) = c(u, v) - f(u, v) c f ( u , v ) = c ( u , v ) − f ( u , v )
Ford-Fulkerson 增广是计算最大流的一类算法的总称。
我们引入一个概念:增广路。
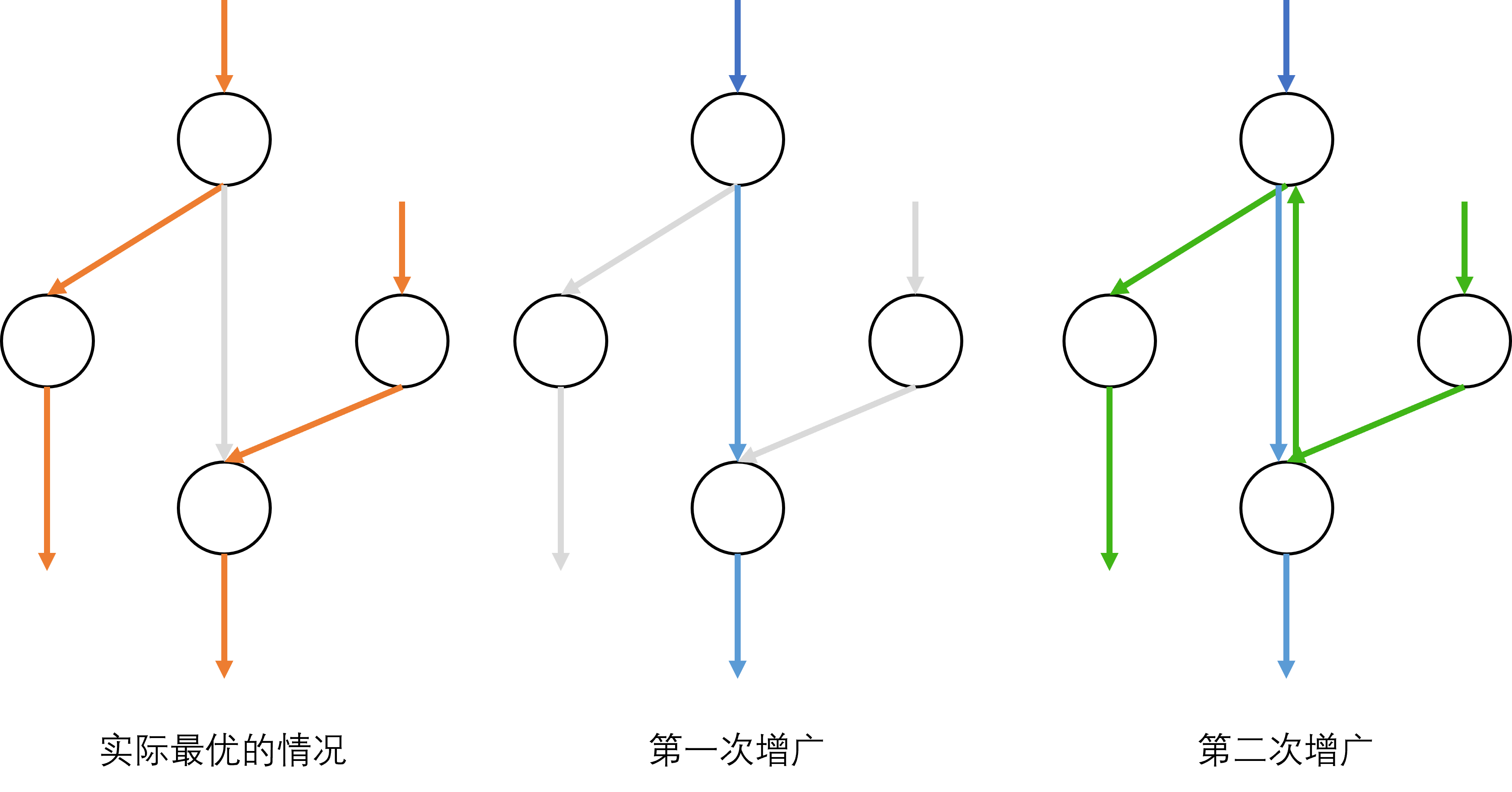
现在对于上面的那个问题,有个暴力的想法:挺奇怪的名字 。
但如果只是单纯的这样明显很随机 。反悔 操作。
我们给每条边都加一个反边,在增广减去原边的流量的时候,我们给反边增加上这个流量。抵消 ,那么就是在反悔 。
实现提示
在代码实现时,我们往往需要支持快速访问反向边的操作。2 2 2 i i i i ⊕ 1 i \oplus 1 i ⊕ 1
在实现中,我们不会记录它的最大流量,我们之后记录它的剩余流量。
我们大致了解了 Ford–Fulkerson 增广的思想,可是如何证明这一方法的正确性呢?G = ( V , E ) G = (V, E) G = ( V , E ) f f f { S , T } \{S, T\} { S , T } ∣ f ∣ = ∥ S , T ∥ \left|f\right| = \left\| S, T\right\| ∣ f ∣ = ∥ S , T ∥
割的含义
对于图 G = ( V , E ) G=(V,E) G = ( V , E ) S S S T = V ∖ S T=V\setminus S T = V ∖ S s ∈ S s\in S s ∈ S t ∈ T t\in T t ∈ T ∥ S , T ∥ = ∑ u ∈ S ∑ v ∈ T c ( u , v ) \left\| S,T\right\| = \sum_{u\in S}\sum_{v\in T}c(u, v) ∥ S , T ∥ = ∑ u ∈ S ∑ v ∈ T c ( u , v )
为了证明最大流最小割定理,我们先从一个引理出发:G = ( V , E ) G = (V, E) G = ( V , E ) f f f ∣ f ∣ ≤ ∥ S , T ∥ \left|f\right| \leq \left\| S, T\right\| ∣ f ∣ ≤ ∥ S , T ∥ { ( u , v ) ∣ u ∈ S , v ∈ T } \{(u, v) | u \in S, v \in T\} { ( u , v ) ∣ u ∈ S , v ∈ T } { ( u , v ) ∣ u ∈ T , v ∈ S } \{(u, v) | u \in T, v \in S\} { ( u , v ) ∣ u ∈ T , v ∈ S }
引理的证明
∣ f ∣ = ∑ u ∈ S f ( u ) = ∑ u ∈ S ( ∑ v ∈ V f ( u , v ) − ∑ v ∈ V f ( v , u ) ) = ∑ u ∈ S ( ∑ v ∈ T f ( u , v ) + ∑ v ∈ S f ( u , v ) − ∑ v ∈ T f ( v , u ) − ∑ v ∈ S f ( v , u ) ) = ∑ u ∈ S ( ∑ v ∈ T f ( u , v ) − ∑ v ∈ T f ( v , u ) ) + ∑ u ∈ S ∑ v ∈ S f ( u , v ) − ∑ u ∈ S ∑ v ∈ S f ( v , u ) = ∑ u ∈ S ( ∑ v ∈ T f ( u , v ) − ∑ v ∈ T f ( v , u ) ) ≤ ∑ u ∈ S ∑ v ∈ T f ( u , v ) ≤ ∑ u ∈ S ∑ v ∈ T c ( u , v ) = ∥ S , T ∥ \begin{aligned}\left|f\right| & = \sum_{u \in S} f(u) \\ & = \sum_{u \in S} \left( \sum_{v \in V} f(u, v) - \sum_{v \in V} f(v, u) \right) \\ & = \sum_{u \in S} \left( \sum_{v \in T} f(u, v) + \sum_{v \in S} f(u, v) - \sum_{v \in T} f(v, u) - \sum_{v \in S} f(v, u) \right) \\ & = \sum_{u \in S} \left( \sum_{v \in T} f(u, v) - \sum_{v \in T} f(v, u) \right) + \sum_{u \in S} \sum_{v \in S} f(u, v) - \sum_{u \in S} \sum_{v \in S} f(v, u) \\ & = \sum_{u \in S} \left( \sum_{v \in T} f(u, v) - \sum_{v \in T} f(v, u) \right) \\ & \leq \sum_{u \in S} \sum_{v \in T} f(u, v) \\ & \leq \sum_{u \in S} \sum_{v \in T} c(u, v) \\ & = \left\| S, T\right\| \\\end{aligned} ∣ f ∣ = u ∈ S ∑ f ( u ) = u ∈ S ∑ ( v ∈ V ∑ f ( u , v ) − v ∈ V ∑ f ( v , u ) ) = u ∈ S ∑ ( v ∈ T ∑ f ( u , v ) + v ∈ S ∑ f ( u , v ) − v ∈ T ∑ f ( v , u ) − v ∈ S ∑ f ( v , u ) ) = u ∈ S ∑ ( v ∈ T ∑ f ( u , v ) − v ∈ T ∑ f ( v , u ) ) + u ∈ S ∑ v ∈ S ∑ f ( u , v ) − u ∈ S ∑ v ∈ S ∑ f ( v , u ) = u ∈ S ∑ ( v ∈ T ∑ f ( u , v ) − v ∈ T ∑ f ( v , u ) ) ≤ u ∈ S ∑ v ∈ T ∑ f ( u , v ) ≤ u ∈ S ∑ v ∈ T ∑ c ( u , v ) = ∥ S , T ∥
为了取等,第一个不等号需要 { ( u , v ) ∣ u ∈ T , v ∈ S } \{(u, v) \mid u \in T, v \in S\} { ( u , v ) ∣ u ∈ T , v ∈ S } { ( u , v ) ∣ u ∈ S , v ∈ T } \{(u, v) \mid u \in S, v \in T\} { ( u , v ) ∣ u ∈ S , v ∈ T }
那么,对于任意网络,以上取等条件是否总是能被满足呢?如果答案是肯定的,则最大流最小割定理得证。
证明
假设某一轮增广后,我们得到流 f f f G G G G G G s s s t t t s s s S S S T = V ∖ S T = V \setminus S T = V ∖ S
显然,{ S , T } \{S, T\} { S , T } ∥ S , T ∥ = ∑ u ∈ S ∑ v ∈ T c f ( u , v ) = 0 \left\| S, T\right\| = \sum_{u \in S} \sum_{v \in T} c_f(u, v) = 0 ∥ S , T ∥ = ∑ u ∈ S ∑ v ∈ T c f ( u , v ) = 0 u ∈ S , v ∈ T , ( u , v ) ∈ E f u \in S, v \in T, (u, v) \in E_f u ∈ S , v ∈ T , ( u , v ) ∈ E f c f ( u , v ) = 0 c_f(u, v) = 0 c f ( u , v ) = 0
( u , v ) ∈ E (u, v) \in E ( u , v ) ∈ E c f ( u , v ) = c ( u , v ) − f ( u , v ) = 0 c_f(u, v) = c(u, v) - f(u, v) = 0 c f ( u , v ) = c ( u , v ) − f ( u , v ) = 0 c ( u , v ) = f ( u , v ) c(u, v) = f(u, v) c ( u , v ) = f ( u , v ) { ( u , v ) ∣ u ∈ S , v ∈ T } \{(u, v) \mid u \in S, v \in T\} { ( u , v ) ∣ u ∈ S , v ∈ T } ( v , u ) ∈ E (v, u) \in E ( v , u ) ∈ E c f ( u , v ) = c ( u , v ) − f ( u , v ) = 0 − f ( u , v ) = f ( v , u ) = 0 c_f(u, v) = c(u, v) - f(u, v) = 0 - f(u, v) = f(v, u) = 0 c f ( u , v ) = c ( u , v ) − f ( u , v ) = 0 − f ( u , v ) = f ( v , u ) = 0 { ( v , u ) ∣ u ∈ S , v ∈ T } \{(v, u) \mid u \in S, v \in T\} { ( v , u ) ∣ u ∈ S , v ∈ T } f f f f f f G G G { S , T } \{S, T\} { S , T } G G G
我们可以简单的认为是 O ( m ∣ f ∣ ) O(m\left|f\right|) O ( m ∣ f ∣ ) m m m ∣ f ∣ \left|f\right| ∣ f ∣ ∣ f ∣ \left|f\right| ∣ f ∣ O ( m ) O(m) O ( m )
当然,不同的实现,复杂度也是大相径庭。4 4 4
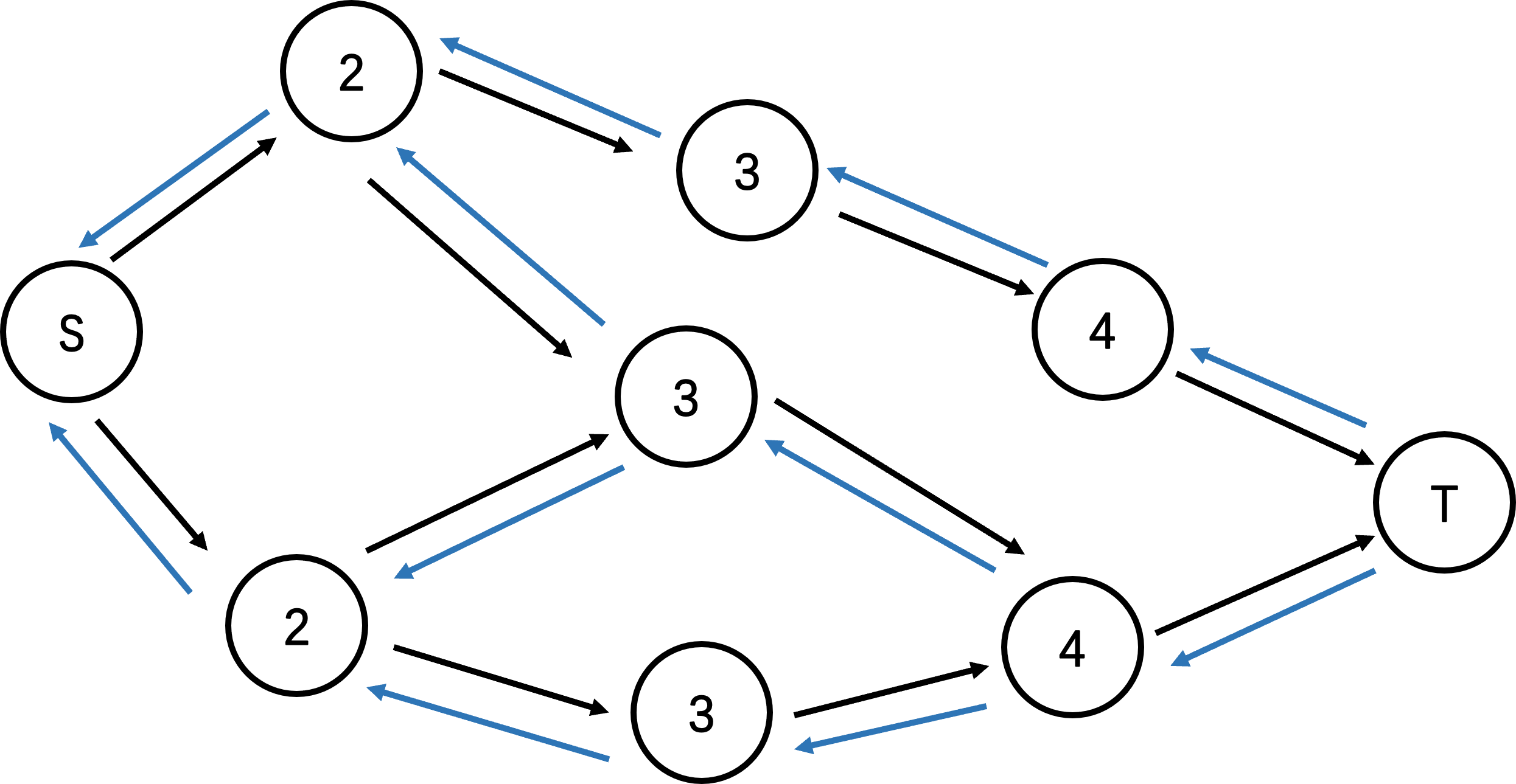
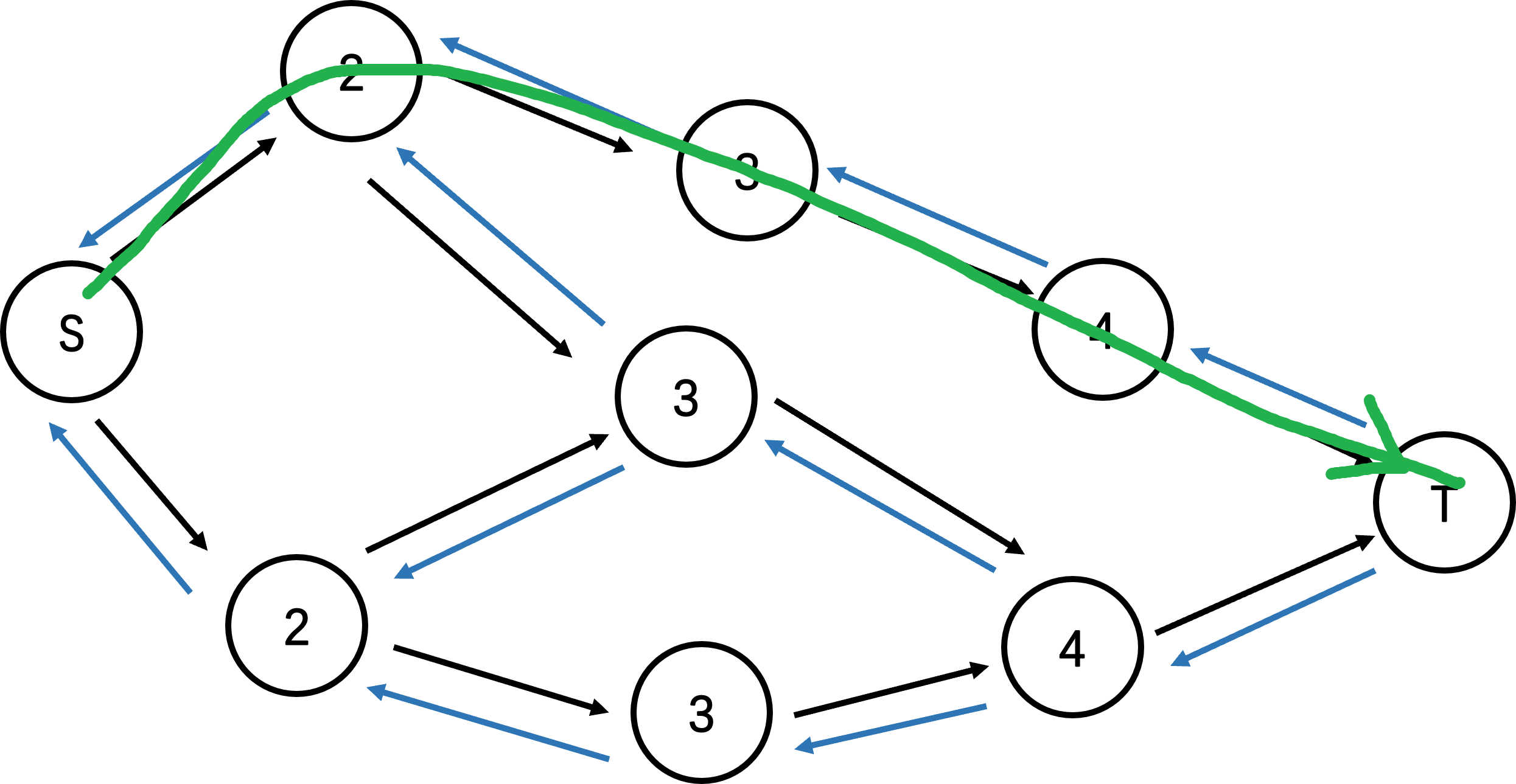
我们用 BFS 从 s s s t t t p p p Δ = m i n ( u , v ) ∈ p c f ( u , v ) \Delta = min_{(u, v) \in p} c_f(u, v) Δ = m i n ( u , v ) ∈ p c f ( u , v ) Δ \Delta Δ Δ \Delta Δ
BFS 轮数的上限是 O ( n m ) O(nm) O ( n m ) O ( m ) O(m) O ( m ) O ( n m 2 ) O(nm^2) O ( n m 2 ) oi-wiki
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <bits/stdc++.h> using namespace std;#define endl '\n' #define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++) #define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--) #define lowbit(x) ((x) & -(x)) #define eb emplace_back #define int long long constexpr int N = 1e6 + 10 ;int n, m, s, t, head[N], tot = 1 , inq[N];struct edge { int v, nxt, w; }e[N]; struct p { int edge, x; }pre[N]; void add (int u, int v, int w) e[++tot] = {v, head[u], w}, head[u] = tot; e[++tot] = {u, head[v], 0 }, head[v] = tot; } bool bfs () memset (inq, 0 , sizeof inq); memset (pre, 0 , sizeof pre); queue<int >q; q.emplace (s), inq[s] = 1 ; while (!q.empty ()){ for (int x = q.front (), i = head[x], v; i; i = e[i].nxt) if (e[i].w && !inq[v = e[i].v]){ inq[v] = 1 , pre[v].x = x, pre[v].edge = i; if (v == t)return 1 ; q.emplace (v); } q.pop (); } return 0 ; } int EK () int ans = 0 ; while (bfs ()){ int mi = 1e10 ; for (int i = t; i != s; i = pre[i].x)mi = min (mi, e[pre[i].edge].w); for (int i = t; i != s; i = pre[i].x)e[pre[i].edge].w -= mi, e[pre[i].edge ^ 1 ].w += mi; ans += mi; } return ans; } int32_t main () cin.tie (0 )->sync_with_stdio (0 ); int u, v, w; cin >> n >> m >> s >> t; while (m--)cin >> u >> v >> w, add (u, v, w); cout << EK (); return 0 ; }
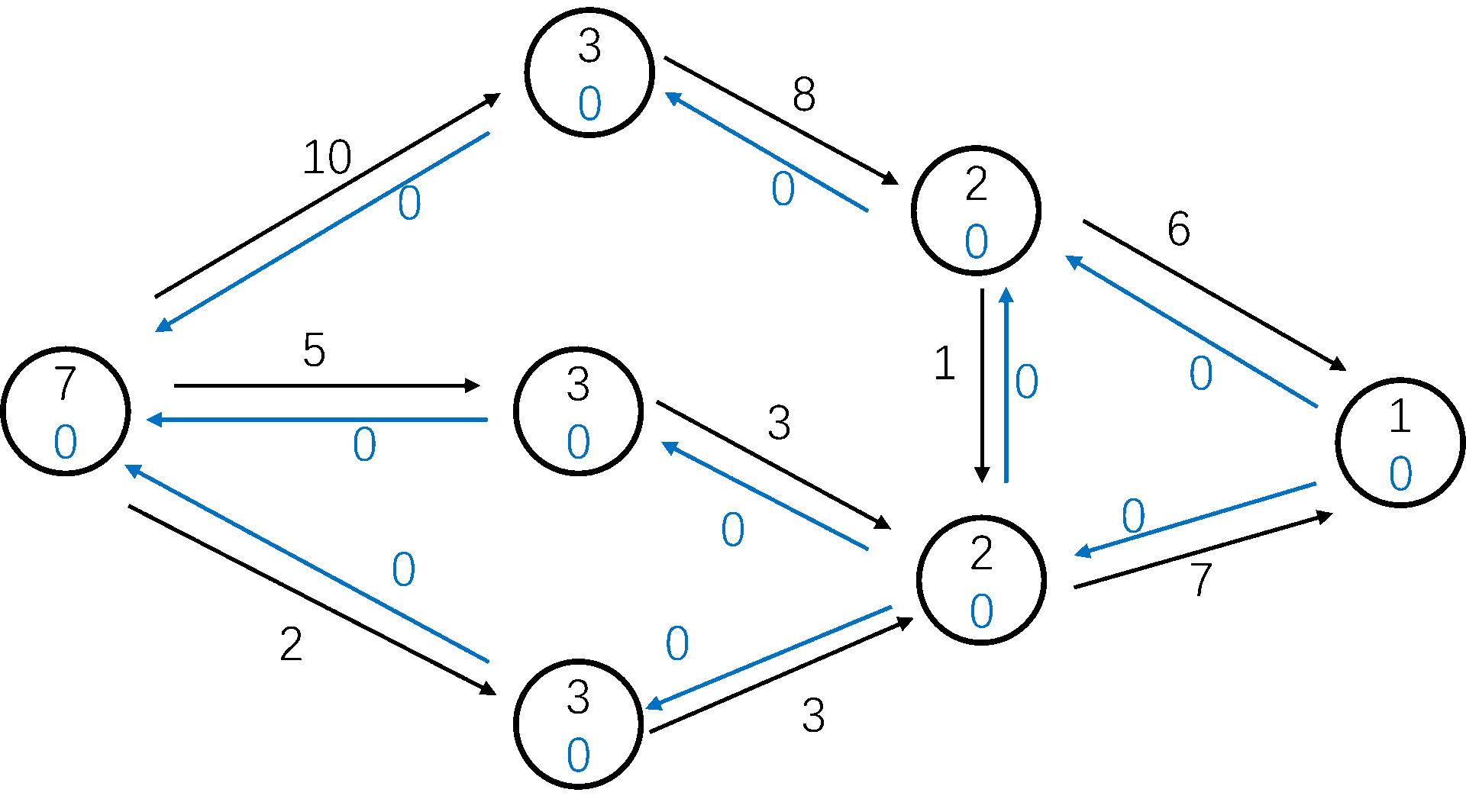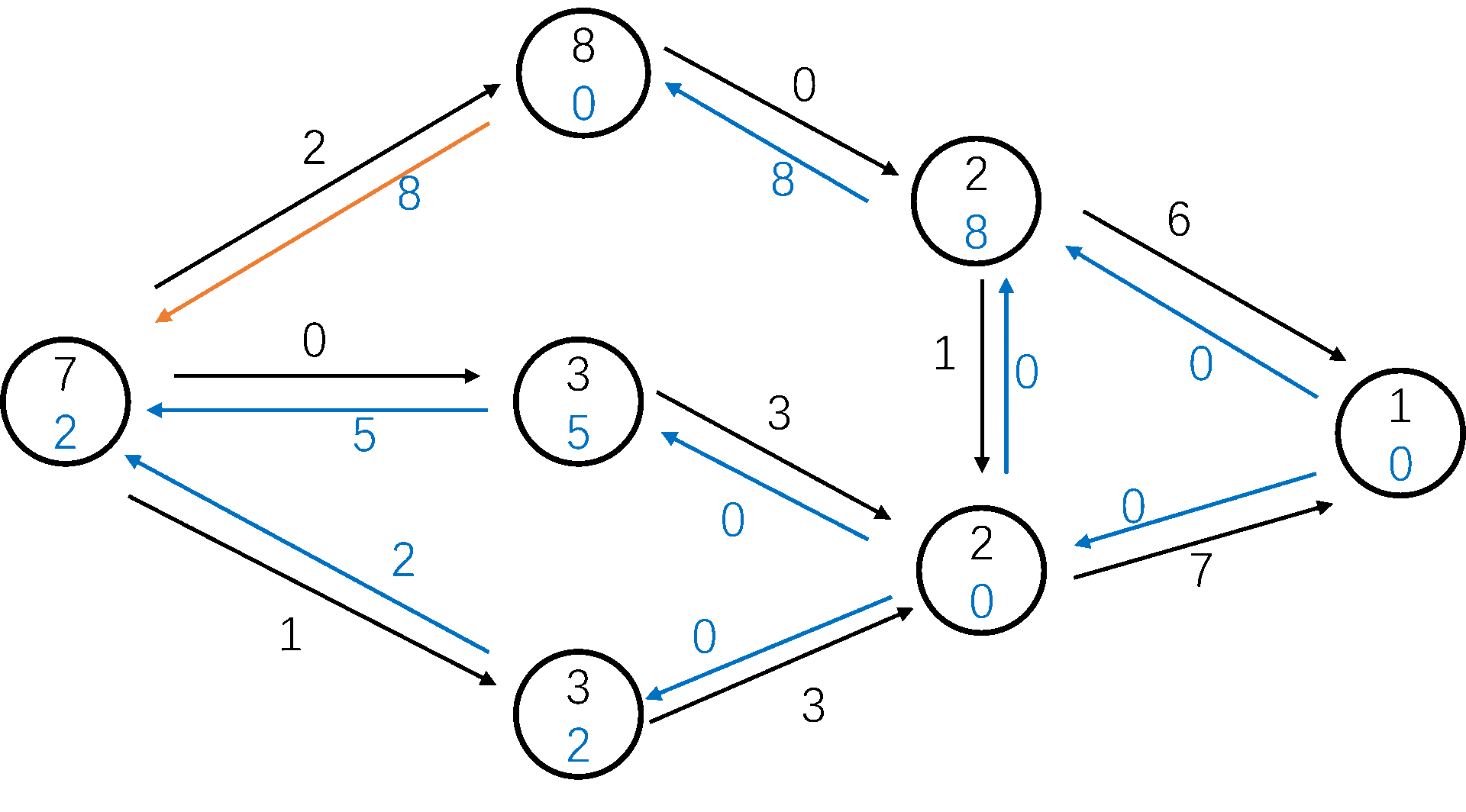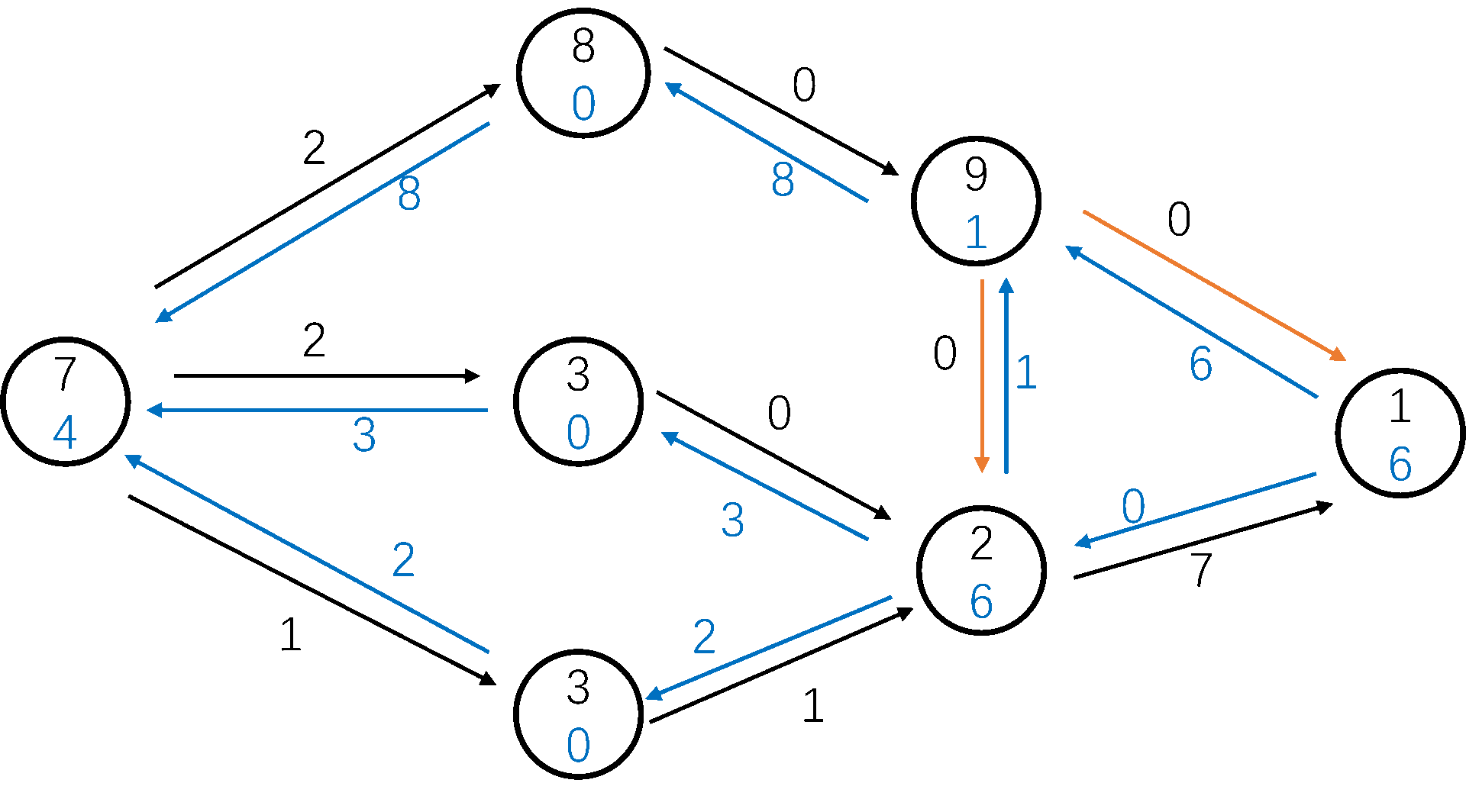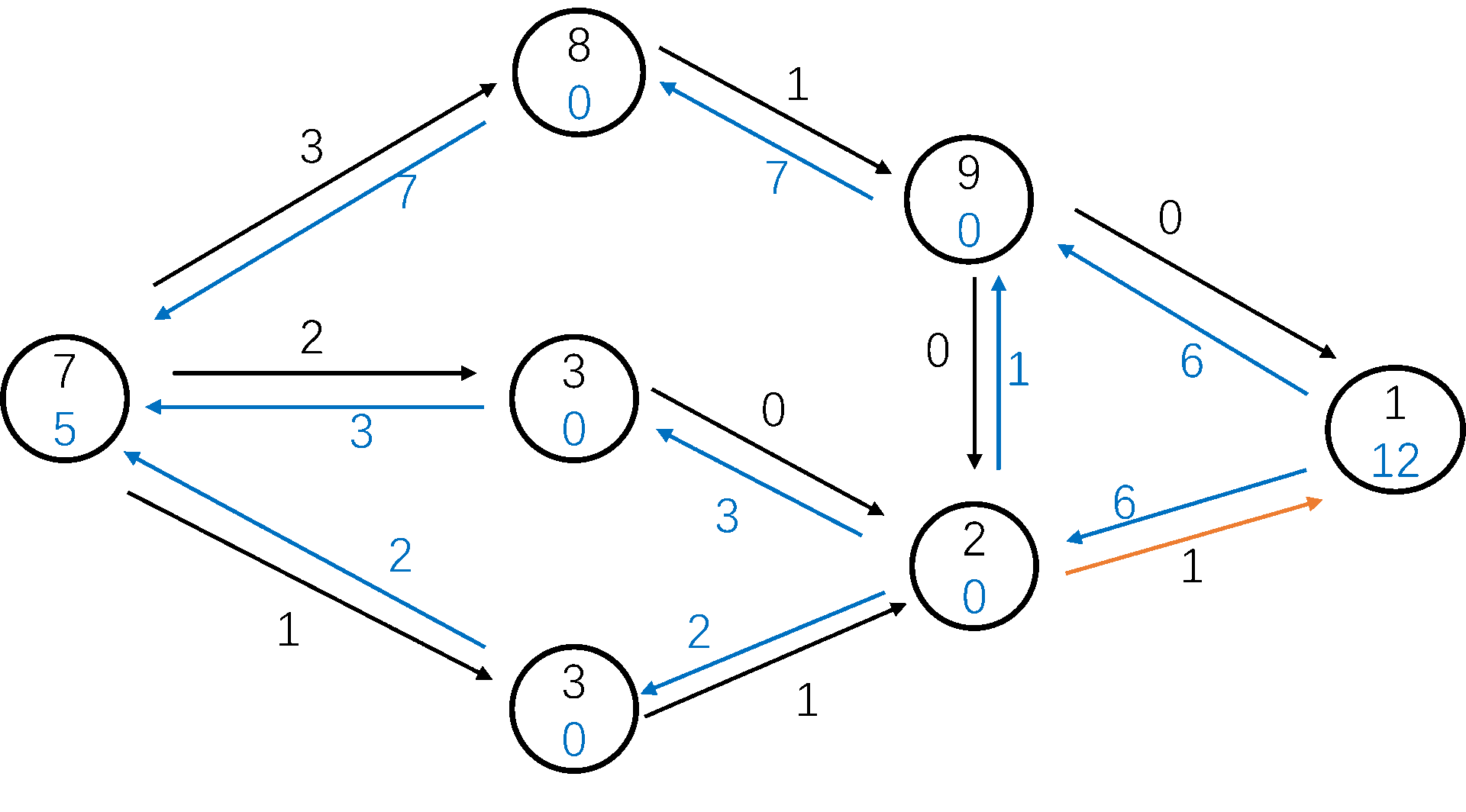
先用 BFS 从 s s s t t t u u u t t t
我们注意 DFS 的过程。u u u u u u n o w now n o w u u u ( u , v ) (u, v) ( u , v ) 当前弧优化 ,前面说了没有当前弧优化的 Dinic 的复杂度是假的 。
我们看这张图(点中是层数,黑边是原边,蓝边是反边):多路增广 ,当然,这只是常数优化。
在单轮 DFS 的时间复杂度是 O ( n m ) O(nm) O ( n m ) n n n O ( n 2 m ) O(n^2m) O ( n 2 m ) 一般卡不满 。
而要是所有边的容量都是 1 1 1 G G G O ( m ) O(m) O ( m ) min ( m 1 2 , n 2 3 ) \min(m^{\frac{1}{2}}, n^{\frac{2}{3}}) min ( m 2 1 , n 3 2 ) u u u 1 1 1 O ( n 1 2 ) O(n^{\frac{1}{2}}) O ( n 2 1 ) 具体的证明见 oi-wiki。
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <bits/stdc++.h> using namespace std;#define endl '\n' #define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++) #define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--) #define lowbit(x) ((x) & -(x)) #define eb emplace_back #define int long long constexpr int N = 2100 ;struct edge { int v, nxt, w; }e[500000 ]; int tot = 1 , head[N], dis[N], t, s, now[N], ans;void add (int u, int v, int w) e[++tot] = {v, head[u], w}, head[u] = tot; e[++tot] = {u, head[v], 0 }, head[v] = tot; } bool bfs () memset (dis, 0 , sizeof dis); queue<int >q; q.emplace (s), dis[s] = 1 ; while (!q.empty ()){ for (int x = q.front (), i = (now[x] = head[x]), v; i; i = e[i].nxt) if (e[i].w && !dis[v = e[i].v])dis[v] = dis[x] + 1 , q.emplace (v); q.pop (); } return dis[t]; } int dfs (int x, int last) if (x == t)return last; int res = last, k; for (int i = now[x], v; i && res; i = e[i].nxt) if (e[now[x] = i].w && (dis[v = e[i].v] == dis[x] + 1 )) if (k = dfs (v, min (res, e[i].w)))e[i].w -= k, e[i ^ 1 ].w += k, res -= k; else dis[v] = 0 ; return last - res; } int32_t main () cin.tie (0 )->sync_with_stdio (0 ); int n, m, u, v; long long w; cin >> n >> m >> s >> t; while (m--)cin >> u >> v >> w, add (u, v, w); while (bfs ())ans += dfs (s, 1e10 ); cout << ans << endl; return 0 ; }
MPM 和 Dinic 其他过程是相似的。O ( n 2 ) O(n^2) O ( n 2 )
MPM 算法需要考虑顶点而不是边的容量。G G G v v v p ( v ) p(v) p ( v )
p i n ( v ) = ∑ ( u , v ) ∈ G ( c f ( u , v ) ) p o u t ( v ) = ∑ ( v , u ) ∈ G ( c f ( v , u ) ) p ( v ) = min ( p i n ( v ) , p o u t ( v ) ) \begin{aligned}
p_{in}(v) &= \sum{(u,v) \in G} (c_f(u, v)) \\
p_{out}(v) &= \sum{(v,u) \in G} (c_f(v, u)) \\
p(v) &= \min (p_{in}(v), p_{out}(v))
\end{aligned}
p i n ( v ) p o u t ( v ) p ( v ) = ∑ ( u , v ) ∈ G ( c f ( u , v ) ) = ∑ ( v , u ) ∈ G ( c f ( v , u ) ) = min ( p i n ( v ) , p o u t ( v ) )
我们称节点 u u u p ( u ) = min p ( v ) p(u) = \min{p(v)} p ( u ) = min p ( v ) u u u u u u p ( u ) p(u) p ( u ) 0 0 0 s s s u u u t t t p ( u ) p(u) p ( u ) s s s t t t
时间复杂度证明见 oi-wiki。
在 Dinic 中,我们要跑多次 BFS,ISAP 就是减少了 BFS 的次数。t t t s s s
接下来不一样的是,在 ISAP 中,我们在 DFS 的时候就会重新处理分层。s s s > n > n > n
相似的,ISAP 也有当前弧优化,和多路增广。GAP 优化 。i i i n u m i num_i n u m i n u m i = 0 num_i = 0 n u m i = 0
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <bits/stdc++.h> using namespace std;#define endl '\n' #define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++) #define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--) #define lowbit(x) ((x) & -(x)) #define eb emplace_back #define int long long constexpr int N = 21000 ;struct edge { int v, nxt, w; }e[500000 ]; int tot = 1 , head[N], dis[N], t, s, now[N], num[N], ans, n;void add (int u, int v, int w) e[++tot] = {v, head[u], w}, head[u] = tot; e[++tot] = {u, head[v], 0 }, head[v] = tot; } void bfs () memset (dis, 0 , sizeof dis); queue<int >q; q.emplace (t), num[dis[t] = 1 ]++; while (!q.empty ()){ for (int x = q.front (), i = head[x], v; i; i = e[i].nxt) if (!dis[v = e[i].v]) num[dis[v] = dis[x] + 1 ]++, q.emplace (v); q.pop (); } } int dfs (int x, int last) if (x == t)return last; int res = last, k; for (int i = now[x], v; i && res; i = e[i].nxt) if (e[now[x] = i].w && (dis[v = e[i].v] + 1 == dis[x])) if (k = dfs (v, min (res, e[i].w))) e[i].w -= k, e[i ^ 1 ].w += k, res -= k; if (!res)return last; if (!--num[dis[x]])dis[s] = n + 1 ; return num[++dis[x]]++, last - res; } int32_t main () cin.tie (0 )->sync_with_stdio (0 ); int m, u, v, w; cin >> n >> m >> s >> t; while (m--)cin >> u >> v >> w, add (u, v, w); bfs (); while (dis[s] <= n)memcpy (now, head, sizeof head), ans += dfs (s, 1e15 ); cout << ans << endl; return 0 ; }
我们换一种思路:
我们允许每个节点都有一个水库,这些储存在非汇原点的水流叫超额流。
总结一下:h u h_u h u u u u c u c_u c u u u u 0 0 0 h s h_s h s n n n u u u u u u ( u , v ) (u, v) ( u , v ) h v = h u − 1 h_v = h_u - 1 h v = h u − 1 ( u , v ) (u, v) ( u , v ) v v v ( u , v ) (u, v) ( u , v ) h x = m i n ( h v ) + 1 h_x = min(h_v) + 1 h x = m i n ( h v ) + 1
上面的算法虽然正确,但上限较紧,在随机数据下比较吃亏,还需要优化。h s h_s h s n n n i h u = i i h_u = i i h u = i n u m i num_i n u m i n u m i = 0 num_i = 0 n u m i = 0 h u > i h_u > i h u > i t t t h u h_u h u n + 1 n + 1 n + 1
HLPP 的时间复杂度十分优秀,为 O ( n 2 m ) O(n^2 \sqrt m) O ( n 2 m )
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #include <bits/stdc++.h> using namespace std;#define endl '\n' #define FL(a, b, c) for(int a = (b), a##end = (c); a <= a##end; a++) #define FR(a, b, c) for(int a = (b), a##end = (c); a >= a##end; a--) #define lowbit(x) ((x) & -(x)) #define int long long #define eb emplace_back constexpr int N = 1300 , M = 3e5 + 10 , inf = 1e5 ;int n, m, s, t, tot = 1 , head[N];struct edge {int v, nxt, w;}e[M];void add (int u, int v, int w) e[++tot] = {v, head[u], w}, head[u] = tot; e[++tot] = {u, head[v], 0 }, head[v] = tot; } int num[N << 1 ], inq[N], c[N], h[N];struct cmp { bool operator () (const int a, const int b) const return h[a] < h[b]; } }; priority_queue<int , vector<int >, cmp>q; bool bfs () queue<int >q; memset (h, 0x7f , sizeof h); num[h[t] = 0 ]++, q.emplace (t); while (!q.empty ()){ for (int x = q.front (), i = head[x], v; i; i = e[i].nxt) if (h[v = e[i].v] > n)num[h[v] = h[x] + 1 ]++, q.emplace (v); q.pop (); } return h[s] <= n; } void relabel (int x) for (int i = head[h[x] = inf, x]; i; i = e[i].nxt) if (e[i].w && h[e[i].v] + 1 < h[x])h[x] = h[e[i].v] + 1 ; } void push (int x) for (int i = head[x], v, d; i && c[x]; i = e[i].nxt) if (e[i].w && h[v = e[i].v] == h[x] - 1 ){ d = min (e[i].w, c[x]); e[i].w -= d, e[i ^ 1 ].w += d, c[x] -= d, c[v] += d; if (!inq[v]) q.emplace (v), inq[v] = 1 ; } } int hlpp () if (!bfs ())return 0 ; h[s] = n, inq[s] = inq[t] = 1 ; for (int i = head[s], v, d; i; i = e[i].nxt) if (h[v = e[i].v] <= inf && (d = e[i].w)){ e[i].w -= d, e[i ^ 1 ].w += d, c[v] += d; if (!inq[v])inq[v] = 1 , q.emplace (v); } while (!q.empty ()){ int x = q.top (); inq[x] = 0 , q.pop (), push (x); if (!c[x])continue ; if (!--num[h[x]]) FL (i, 1 , n)if (i != s && h[i] <= inf && h[i] > h[x])h[i] = max (h[i], n + 1 ); relabel (x), ++num[h[x]], q.emplace (x), inq[x] = 1 ; } return c[t]; } int32_t main () cin.tie (0 )->sync_with_stdio (0 ); int u, v, w; cin >> n >> m >> s >> t; while (m--)cin >> u >> v >> w, add (u, v, w); cout << hlpp (); return 0 ; }
网络流主要考查建图,一般 Dinic 或 ISAP 就够了。
新建 s , t s,t s , t s s s 1 1 1 t t t O ( n n ) O(n\sqrt{n}) O ( n n )
将每个点 u u u u 0 , y 1 u_0, y_1 u 0 , y 1 ( u , v ) (u, v) ( u , v ) u 0 , v 1 u_0, v_1 u 0 , v 1 s s s a n s = n − s ans = n - s a n s = n − s n n n 洛谷 P2764 ,CF1630F 。
题目:n n n A , B A,B A , B A A A a i a_i a i B B B b i b_i b i u i , v i , w i u_i,v_i,w_i u i , v i , w i u i u_i u i v i v_i v i w i w_i w i
我们对于设置源点 s s s t t t i i i s s s a i a_i a i t t t b i b_i b i u , v , w u,v,w u , v , w u , v u,v u , v w w w
注意到当源点和汇点不相连时,代表这些点都选择了其中一个集合。s s s t t t A A A B B B AGC38F ,洛谷 P4313
即给定一张有向图,每个点都有一个权值(int 范围),你需要选择一个权值和最大的子图,使得子图中每个点的后继都在子图中。
建立超级源点 s s s t t t u u u s s s u u u u u u u u u t t t ∞ \infty ∞
有 n n n x i x_i x i x i x_i x i [ 1 , m ] [1,m] [ 1 , m ] j j j a i , j a_{i,j} a i , j x u ≤ x v + w x_u \le x_v + w x u ≤ x v + w x i x_i x i m + 1 m + 1 m + 1 s → x i , 1 , → x i , 2 → … → x i , m + 1 → t s\rightarrow x_{i, 1}, \rightarrow x_{i, 2} \rightarrow \ldots \rightarrow x_{i, m + 1} \rightarrow t s → x i , 1 , → x i , 2 → … → x i , m + 1 → t s → x i , 1 = ∞ , x i , m + 1 → t = ∞ , x i , j → x i , j + 1 = a i , j s\rightarrow x_{i, 1} = \infty, x_{i, m + 1} \rightarrow t = \infty, x_{i, j} \rightarrow x_{i, j + 1} = a_{i, j} s → x i , 1 = ∞ , x i , m + 1 → t = ∞ , x i , j → x i , j + 1 = a i , j u , v , w u, v, w u , v , w x v , j + w → x u , j = ∞ x_{v, j + w} \rightarrow x_{u, j} = \infty x v , j + w → x u , j = ∞ 洛谷 P3227 ,洛谷 P6054 。